AIモデルがどれだけ優秀でも、流し込むデータがバラバラだったり、未来の情報をうっかり混ぜてしまったりすると、予測は簡単に壊れます。
今回は、時系列データを扱う上で絶対に守りたいルールと、TensorFlow で賢くデータを処理するコツを解説します。すでに 時系列データの基本 を読んだ人や、TensorFlow 公式チュートリアルの全体像 をつかみたい人が、その次に読む記事としてちょうどよい内容です。
1. 「未来のカンニング」を徹底的に防ぐ
時系列予測で最も怖いのが、データリーク です。これは、学習中に本来まだ見えてはいけない未来の情報が混ざってしまう状態を指します。
混ぜるな危険
画像認識のような普通の機械学習では、データをランダムにシャッフルしても問題になりにくい場面があります。しかし、時系列で同じことをすると、明日の情報を見たうえで今日を当てるような状態になり、評価が不自然によく見えてしまいます。
- 鉄則: データは必ず古い順のまま扱う
- 安全な分割: 訓練、検証、テストの順番を崩さない
- 注意点: 前処理の基準値も訓練データから作る
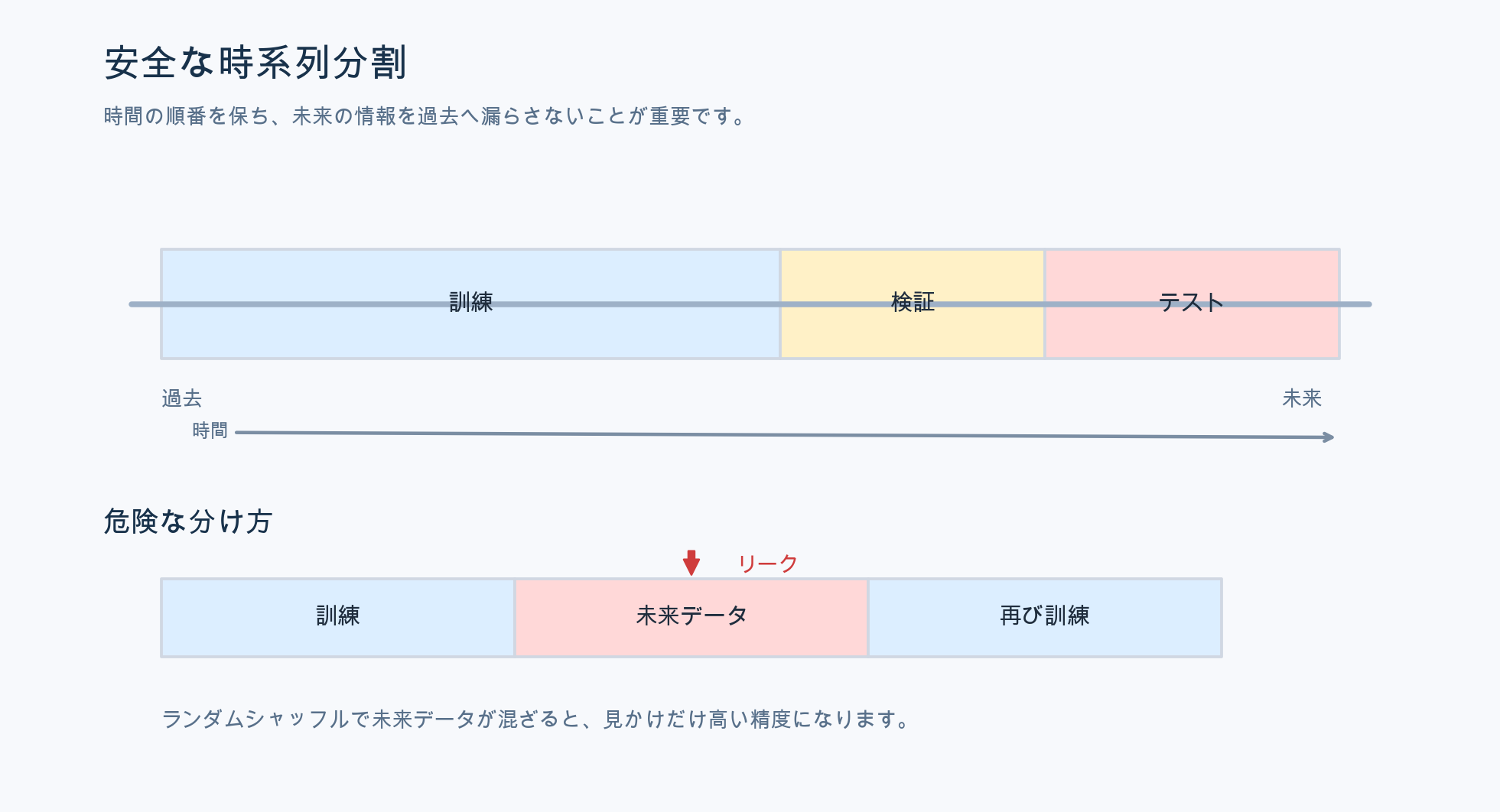
「モデルの精度が高い」のではなく、「未来を先に見ていたから当たっただけ」にならないようにすることが、実戦で使える AI を作る第一歩です。
2. 単位を揃える「標準化」の魔法
AI は、人間のように「1000m と 1km は同じ意味だ」と自然に理解してくれるわけではありません。値のスケールがそろっていないと、学習が不安定になりやすくなります。
そこでよく使うのが、平均を 0、標準偏差を 1 にそろえる標準化です。
$$ z = \frac{x - \mu_{train}}{\sigma_{train}} $$
ここで重要なのは、訓練データの平均と標準偏差だけを使う ことです。検証データやテストデータ自身の平均を使ってしまうと、それも未来情報の混入になります。
import pandas as pd
def split_by_time(frame: pd.DataFrame) -> tuple[pd.DataFrame, pd.DataFrame, pd.DataFrame]:
n = len(frame)
train_end = int(n * 0.7)
val_end = int(n * 0.9)
train_df = frame.iloc[:train_end].copy()
val_df = frame.iloc[train_end:val_end].copy()
test_df = frame.iloc[val_end:].copy()
return train_df, val_df, test_df
def standardize_by_train_stats(
train_df: pd.DataFrame,
val_df: pd.DataFrame,
test_df: pd.DataFrame,
) -> tuple[pd.DataFrame, pd.DataFrame, pd.DataFrame]:
train_mean = train_df.mean()
train_std = train_df.std().replace(0, 1)
train_scaled = (train_df - train_mean) / train_std
val_scaled = (val_df - train_mean) / train_std
test_scaled = (test_df - train_mean) / train_std
return train_scaled, val_scaled, test_scaledこの流れなら、訓練用の基準で全データを同じ物差しにそろえられます。プロっぽい派手な裏技ではありませんが、こういう地味なルールが予測の信頼性を支えています。
3. WindowGenerator: データの「切り出し窓」
TensorFlow の公式チュートリアルで中心となるのが WindowGenerator という考え方です。長い一本道のデータに対して「のぞき窓」を少しずつずらしながら、入力と正解ラベルをまとめて切り出していくイメージです。

- Input Width: 過去何ステップを参考にするか
- Label Width: 未来何ステップを予測するか
- Shift: 入力の終わりから予測対象までの距離
この窓を定義しておけば、大量の時系列データを人の手で 1 件ずつ切り出す必要がなくなります。実装を自動化しながら、切り出しミスも減らせます。
import tensorflow as tf
class WindowGenerator:
def __init__(self, input_width: int, label_width: int, shift: int):
self.input_width = input_width
self.label_width = label_width
self.shift = shift
self.total_window_size = input_width + shift
self.input_slice = slice(0, input_width)
self.label_start = self.total_window_size - label_width
self.labels_slice = slice(self.label_start, None)
def split_window(self, features: tf.Tensor) -> tuple[tf.Tensor, tf.Tensor]:
inputs = features[:, self.input_slice, :]
labels = features[:, self.labels_slice, :]
return inputs, labelsこの考え方を押さえておくと、「モデル設計」と「データ準備」を切り分けて考えやすくなります。LSTM でも Dense でも、まず同じ窓で公平に比較できるからです。
4. tf.data で高速道路を作る
データが数万件、数十万件と増えると、メモリの使い方や読み込み速度が効いてきます。ここで役立つのが tf.data と timeseries_dataset_from_array です。
import tensorflow as tf
def make_dataset(data, total_window_size: int, batch_size: int = 32):
dataset = tf.keras.utils.timeseries_dataset_from_array(
data=data,
targets=None,
sequence_length=total_window_size,
sequence_stride=1,
shuffle=True,
batch_size=batch_size,
)
dataset = dataset.prefetch(tf.data.AUTOTUNE)
return datasetここでの shuffle=True は、窓の中身の時間順を壊すわけではなく、切り出した窓のまとまりを並べ替える という意味です。そのため、時系列のルールを守りつつ学習効率を上げられます。
M4 MacBook Air のような環境では、CPU 側でデータを準備しながら GPU や Metal バックエンド側に処理を渡す流れが素直に効いてきます。データ供給が詰まらないだけで、学習全体がかなり滑らかになります。
5. 安全で速いパイプラインの組み立て例
ここまでの内容をつなげると、実運用では次の順番で考えると整理しやすいです。
- 元データを時系列順に並べる
- 訓練、検証、テストへ時間順に分割する
- 訓練データの統計量で標準化する
- WindowGenerator の考え方で窓を切り出す
tf.dataでバッチ化し、prefetch で流れを止めにくくする
この順番を守ると、精度の見かけ倒しを防ぎながら、学習のスループットも上げやすくなります。
6. まとめ
時系列予測では、モデルそのものより先に、データの扱い方で勝負が決まることが少なくありません。
- 時系列は順序が命。未来情報を混ぜない。
- 標準化は訓練データの基準で行う。
- WindowGenerator で切り出しを自動化してミスを減らす。
tf.dataを使って、学習へスムーズに流し込む。
正しく仕込まれたデータは、AI の学習を驚くほど安定させます。次に読むなら、データをどう扱うかの全体像を見渡せる TensorFlow 公式チュートリアル解説 や、時系列そのものの見方を整理した 時系列データのふしぎ もつながりがよいはずです。