前回の記事では、LSTMが「長期記憶の高速道路」を持つことで、RNNの弱点である「忘れっぽさ」を克服していることを解説しました。
今回は、Googleが開発したオープンソースライブラリ TensorFlow(Keras) を使い、実際に簡単な時系列データを学習させて、その精度の差を数値で確認してみます。
1. 検証のセットアップ
複雑なデータを使う前に、まずは基本となる「サイン波(正弦波)」の予測で比較します。 「過去50ステップのデータから、次の1ステップを予測する」というタスクを与え、RNNとLSTMでどれくらい誤差(Loss)に差が出るかを見てみましょう。
モデルの構築コード
Kerasを使うと、RNNもLSTMも驚くほど簡単に記述できます。
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, LSTM, SimpleRNN
# シンプルなRNNモデル
model_rnn = Sequential([
SimpleRNN(50, input_shape=(50, 1)),
Dense(1),
])
# LSTMモデル
model_lstm = Sequential([
LSTM(50, input_shape=(50, 1)),
Dense(1),
])構造はほぼ同じですが、内部の「セル」の仕組みが違うだけで結果がどう変わるかがポイントです。
2. 学習プロセスの比較
私のメインマシンである M4 MacBook Air で学習を回してみると、その処理速度の速さに驚かされます。LSTMは計算が複雑な分、RNNよりも少し時間がかかりますが、M4チップのGPU(Metal)を活用すれば、ストレスなく検証が完了します。
評価指標:平均二乗誤差(MSE)
学習が進むにつれて、予測値と正解値のズレがどう変化したかを確認します。
$$ MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 $$
- SimpleRNN: 最初のうちは順調に下がりますが、ある程度のところで停滞します。過去50ステップの情報を完全に保持しきれず、予測が「なんとなく」の形になってしまう傾向があります。
- LSTM: RNNよりも収束が速く、最終的な誤差も圧倒的に小さくなります。「高速道路」のおかげで、50ステップ前のパターンの影響を最後まで正確に計算できている証拠です。
3. 結果の可視化
実際に予測させたグラフを比較すると、その差は一目瞭然です。
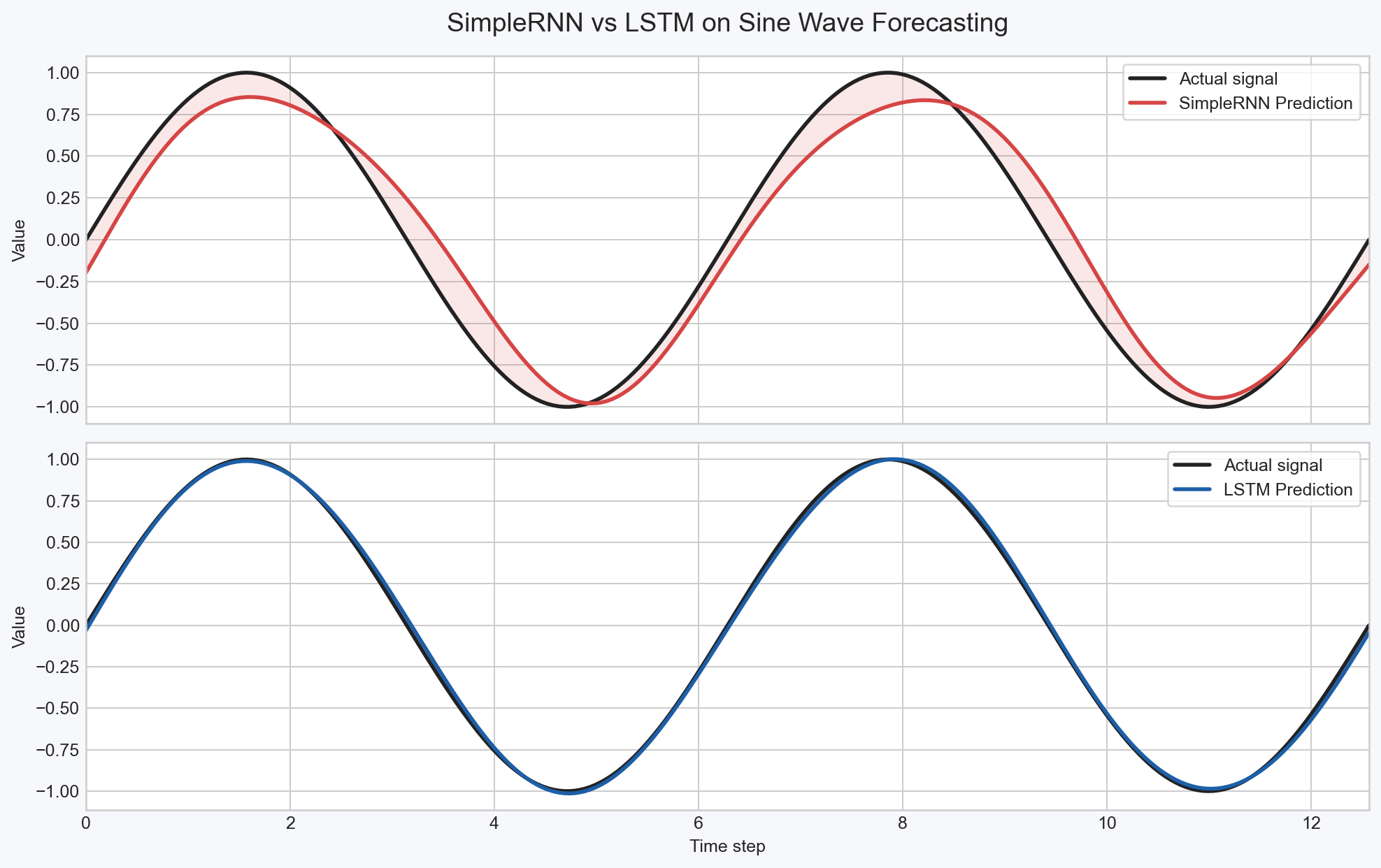
- RNNの予測: 山や谷のピークで少しズレが生じたり、周期が長くなると形が崩れ始めます。
- LSTMの予測: 正解データとほぼ重なるような、滑らかな予測線を引くことができます。
4. 結論:なぜ実践でもLSTMが選ばれるのか
今回の単純なサイン波でさえ、精度の差がはっきりと出ました。これが 「工場の電力需要予測」や「季節変動のある売上予測」 のような、複雑な周期性と長期的なトレンドが混ざり合うデータであれば、その差はさらに決定的になります。
RNNは直近の動きに引きずられがちですが、LSTMは「去年の同じ時期はどうだったか」という長期的な文脈を高速道路(Cell State)を通じて維持できるため、より実戦的な予測が可能になります。